Diffbot Knowledge Graph
Search a structured graph of the public web—entities and facts instead of just links.
Developer-friendly ASR API offering streaming, async, and audio intelligence (diarization, topics, sentiment).
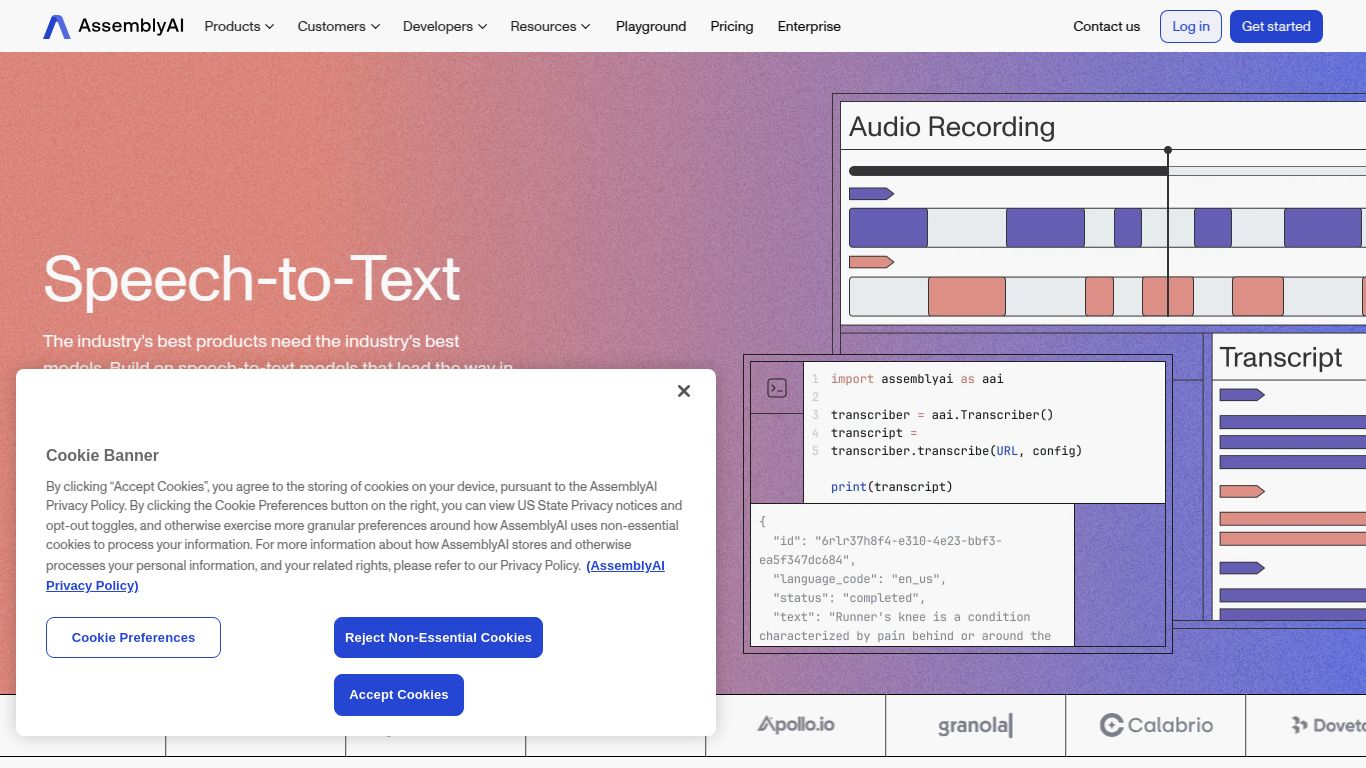
In a world overflowing with audio and video content, unlocking the valuable data trapped within voice is a game-changer. Meet AssemblyAI Speech-to-Text, a state-of-the-art API platform designed by AssemblyAI to provide developers with incredibly accurate and feature-rich transcription services. More than just converting speech to words, this powerful tool offers a suite of AI models that understand and analyze voice data, making it a go-to solution for building sophisticated, voice-enabled applications.

AssemblyAI specializes in processing spoken audio, whether it’s from a pre-recorded file or a live stream. Its core capability is to take audio or video inputs and produce highly accurate, formatted text transcripts. This functionality extends to both real-time transcription for live events and asynchronous batch processing for large volumes of media files. The platform is built around a powerful API, meaning its capabilities are designed to be integrated directly into your own products and workflows, rather than being a standalone consumer application.
What sets AssemblyAI apart is its deep bench of intelligent features that go far beyond simple transcription. These tools allow you to extract maximum value from every conversation.
AssemblyAI offers a developer-friendly pricing model that is both accessible for small projects and scalable for enterprise-level needs. The structure is designed to be straightforward and predictable.
This tool is primarily an API, making it the perfect choice for individuals and teams who build software. The target audience includes:
The speech-to-text market includes giants like Google and Amazon, as well as specialized competitors. Here’s how AssemblyAI carves out its space.
While Google offers a very robust and scalable platform, AssemblyAI often stands out for its comprehensive suite of built-in AI models. With AssemblyAI, features like summarization, topic detection, and PII redaction are seamlessly integrated, whereas with Google, you might need to combine multiple services to achieve the same result. Many developers also praise AssemblyAI for its clear documentation and superior developer experience.
Whisper is a powerful open-source model known for its exceptional accuracy. However, Whisper is a model, not a fully-managed API service. Using it effectively requires handling infrastructure, scaling, and maintenance. AssemblyAI provides a fully-managed API that not only matches Whisper’s accuracy but also adds critical production-ready features like speaker diarization and real-time streaming, which are more complex to implement with the base Whisper model.
Rev is a strong competitor known for its high accuracy, often combined with human review services. AssemblyAI differentiates itself by focusing purely on a best-in-class, AI-driven API. It competes strongly on price and its broader range of integrated AI analysis tools, making it a more versatile and often more cost-effective choice for teams that need more than just a raw transcript.
